¿Qué son las tablas hash?
La tabla hash o tabla de dispersión es una estructura de datos que surge de la idea de acceder a un elemento mediante una clave. Por ejemplo, imagina que en esta tabla queremos acceder a los datos de la persona Juan.
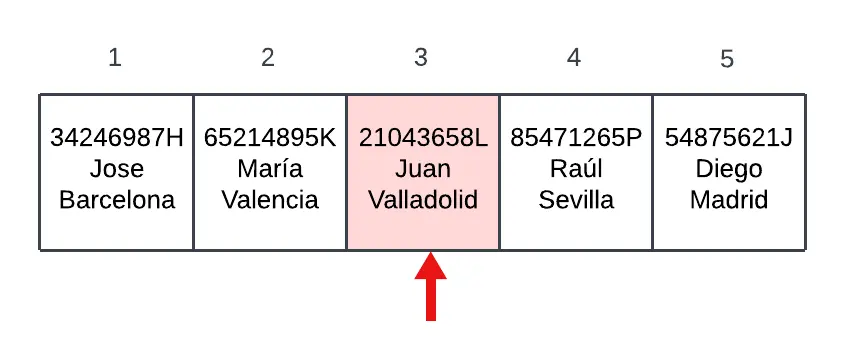
Una manera sería recorrer toda la tabla hasta encontrarlo, pero esto no sería eficiente porque, ¿qué pasaría si Juan estuviera último? El acceso por clave aparece para solucionar este problema. Primero, escogeremos una pieza de información única para cada persona y la estableceremos como clave, por ejemplo el DNI. Lo que se hace en los mapas hash es, mediante una serie de cálculos sobre la clave, le asigna una posición en la tabla. De esta forma solo con la clave obtendremos la posición donde se encuentra la información. No tendremos que mirar en otras posiciones.
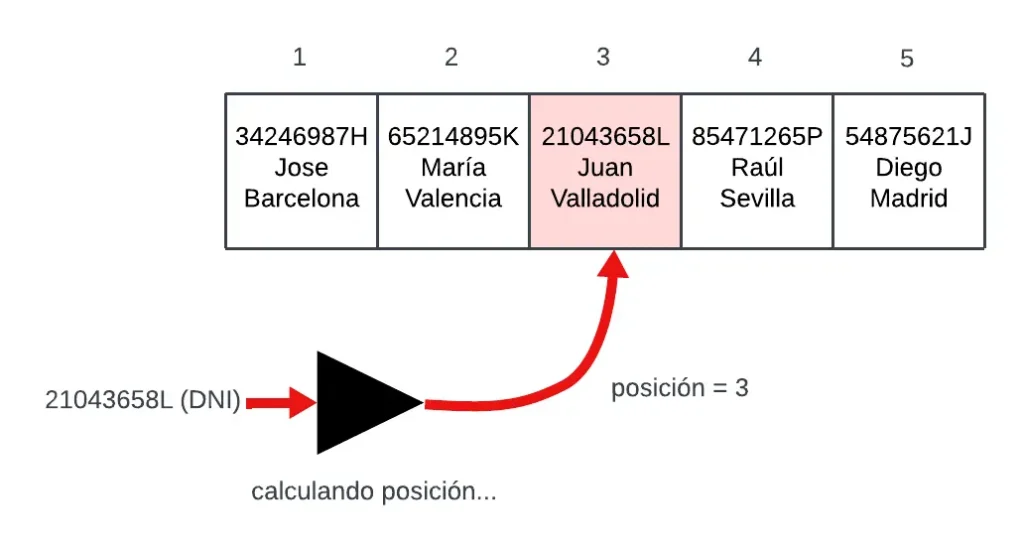
En resumen, las tablas de dispersión son vectores a los cuales se les añade información asociada a una clave. Para saber donde colocar la información se llevan a cabo unos cálculos sobre la clave conocidos como hashing, de ahí el nombre de esta estructura.
Función de hash: asignar a una clave una posición
Siguiendo con el ejemplo anterior, necesitaremos que estos cálculos, dada una clave, nos devuelvan un valor entre [1, 5]. En definitiva, estamos diciendo que necesitamos una función ‘h’ que dada una clave ‘k’ devuelva un valor entre [1, 5]. Está función se define como función de hash y se denota como h(k). En el ejemplo anterior h(21043658L) = 3.
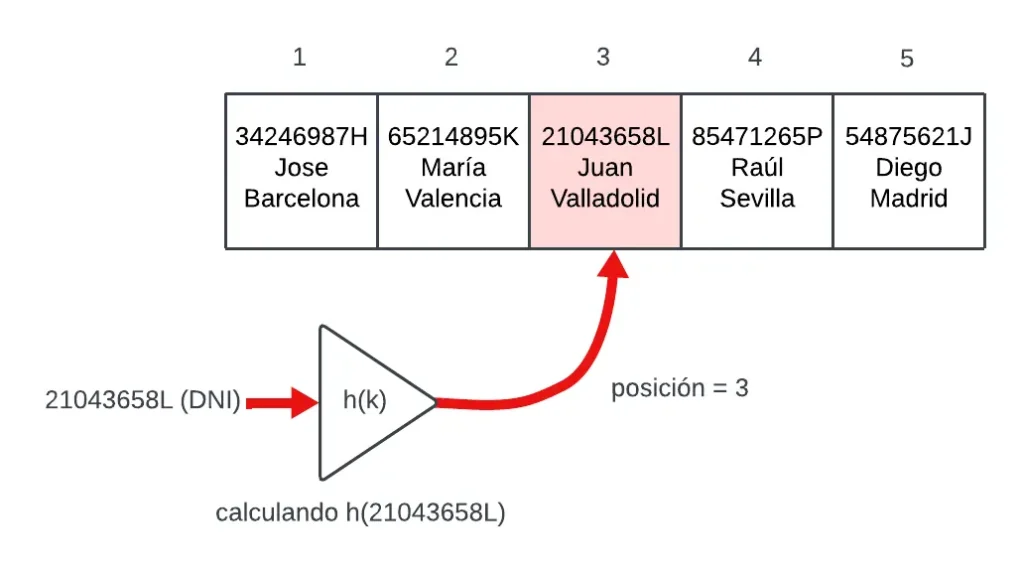
Ahora podemos comprender que el diseño de una tabla de hash consiste en insertar las parejas (clave, información) en la posición h(clave) de un vector. La dificultad radica en diseñar estas funciones h(k) ya que deben cumplir una serie de propiedades fundamentales.
Dados un vector de B posiciones, un espacio de claves K y una función de hash h(k) se debe cumplir que:
- PROPIEDAD 1: h(k) debe de ser eficiente a la hora de calcularse.
- PROPIEDAD 2: h(k) devolverá un valor dentro del intervalo [0, B) para toda clave en el conjunto K.
- PROPIEDAD 3: h(k) siempre devolverá el mismo valor para la misma clave.
- PROPIEDAD 4: h(k) tiene que poder devolver todos los valores dentro del intervalo [0, B) con la misma probabilidad.
Una vez diseñada nuestra función nos aparecerá un nuevo problema. Inevitablemente, puede haber dos claves k1 y k2 que sean sinónimas, es decir, que h(k1) = h(k2). Esto implica que dos informaciones distintas irán a parar a la misma posición en la tabla. ¿Qué hacemos entonces? Hay dos opciones: convertimos las posiciones del vector en listas de múltiples claves (dispersión abierta) o buscamos una nueva posición mediante una nueva función (dispersión cerrada).
Tabla hash con dispersión abierta
Esta estrategia consiste en colocar una lista enlazada en cada posición del vector. Así, si dos claves van a parar al mismo sitio, añadiremos una después de otra. Te lo enseño con este diagrama donde para una clave k4, la posición que le asigna la función de hash está ocupada:
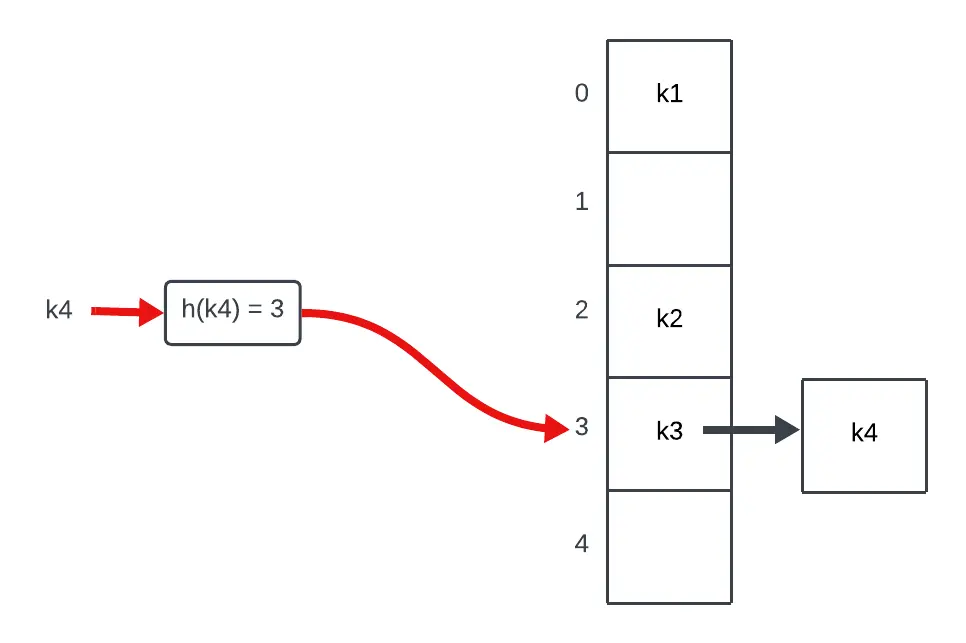
Puedes comprovar que en la posición 3 (donde colisionan k3 y k4) se empieza una nueva lista en la que k3 es el primer elemento y k4 el segundo. Aquí surge un posible problema, ¿qué pasaría si se fueran acumulado elementos en esta lista y no en otras posiciones del vector? Pues que ya no tendríamos acceso directo por clave porque para encontrar un elemento deberíamos recorrer toda la lista. No obstante, hoy en día las funciones de hash son tan buenas que no se acostumbra a ver más de dos elementos en una posición del vector, en consecuencia, sigue siendo muy eficiente.
Tabla hash con dispersión cerrada
En este caso, en vez de tener una sola función tendremos múltiples, es decir, una familia de funciones h0, h1, h2, h3, etc. Las posiciones del vector, en vez de ser listas, tienen la estructura (clave, información, marca) donde la marca puede ser:
- OCUPADO: la posición contiene una pareja (clave, información).
- LIBRE: la posición no contiene nada.
- BORRADO: la posición contuvo una pareja (clave, información) que fue borrada.
Veamos como se realizan las operaciones básicas para este modelo de tabla hash.
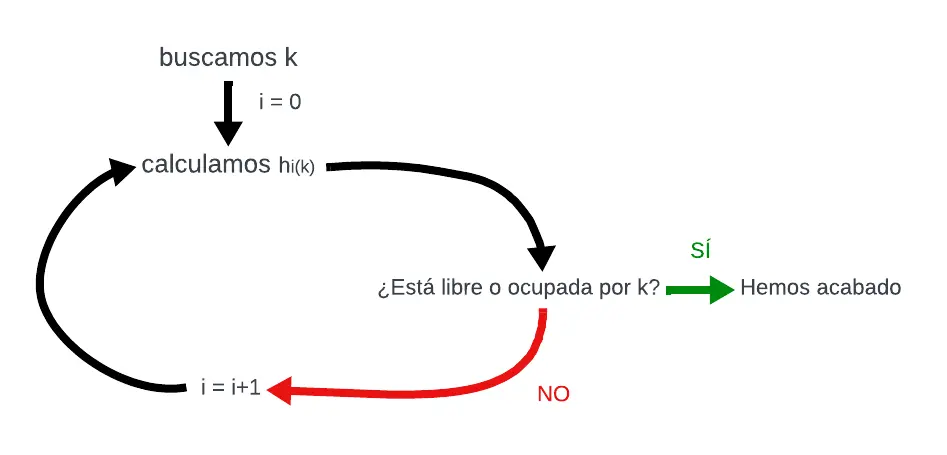
Búsqueda
La búsqueda en una tabla de dispersión cerrada consistirá en encontrar la pareja (clave, información) en una posición de la tabla. Para lograrlo, empezaremos calculando h0(k). Entonces, nos encontraremos con tres casos:
- CASO 1: La posición devuelta por h0(k) está marcada como libre –> LA CLAVE NO ESTÁ EN LA TABLA
- CASO 2: La posición devuelta por h0(k) contiene la clave –> HEMOS ENCONTRADO LA CLAVE
- CASO 3: La posición devuelta por h0(k) contiene una clave pero no es la que estamos buscando
En las primeras dos situaciones habríamos acabado pero, ¿qué hacemos en la tercera? Pues repetiremos el proceso pero calculando h1(k). Este proceso se repetiría hasta agotar todas las funciones que tengamos. En ese caso también podremos descartar que la clave está en la tabla.
Inserción
Para añadir un elemento a una tabla de dispersión cerrada deberemos usar la família de funciones otra vez. Primero, haremos una búsqueda hasta encontrar la clave que inserimos, una posición libre o agotar todas las funciones de hash. En el primer caso, actualizaremos la clave con la nueva información. En el segundo, si hemos pasado por alguna posición borrada, inseriremos la clave allí. Si no, la inseriremos en la posición libre que hemos encontrado. Finalmente, si hemos agotado todas las funciones, deberemos dejar la tabla tal y como estaba.
Eliminación
Si lo que queremos es eliminar una clave de la tabla de hash, deberemos aplicar el algoritmo de búsqueda hasta encontrar la clave, una posición libre o agotar todas las funciones. Si la encontramos, la marcamos como borrada. Si no, podemos afirmar que la clave no está en la tabla.
Tablas hash en Java
Java, en la JCF (Java Collections Framework), ofrece HashMap<K, V> como implementación de las tablas de dispersión abierta. Esta clase hereda los métodos de AbstractMap<K, V>, que implementa la interfície Map<K, V>.
import java.util.HashMap;
public class Main {
public static void main(String[] args) {
HashMap<Integer,Integer> tabla = new HashMap<>(10); // crear tabla de hash de 10 posiciones
tabla.put(1, 1); // insertar la pareja (clave: 1, valor: 1)
System.out.println(tabla.get(1)); // obtener el elemento asociado a 1 (1)
tabla.remove(1); // eliminar la clave 1
System.out.println(tabla.isEmpty()); // mirar si está vacía (true)
}
}Si quieres entrar más en detalle, te dejo aquí la documentación de estas clases e interfície:
Tabla hash en otros lenguajes
Las tablas de dispersión son una estructura de datos que está en todos lados. Te dejo estos excelentes artículos que puedes leer para encontrar documentación sobre las tablas hash en otros lenguajes de programación como Python y Javascript.